
- DATE:
- AUTHOR:
- The LangChain Team
LangSmith
🔁 Self-improving LLM evaluators in LangSmith
DATE:
AUTHOR:
The LangChain Team
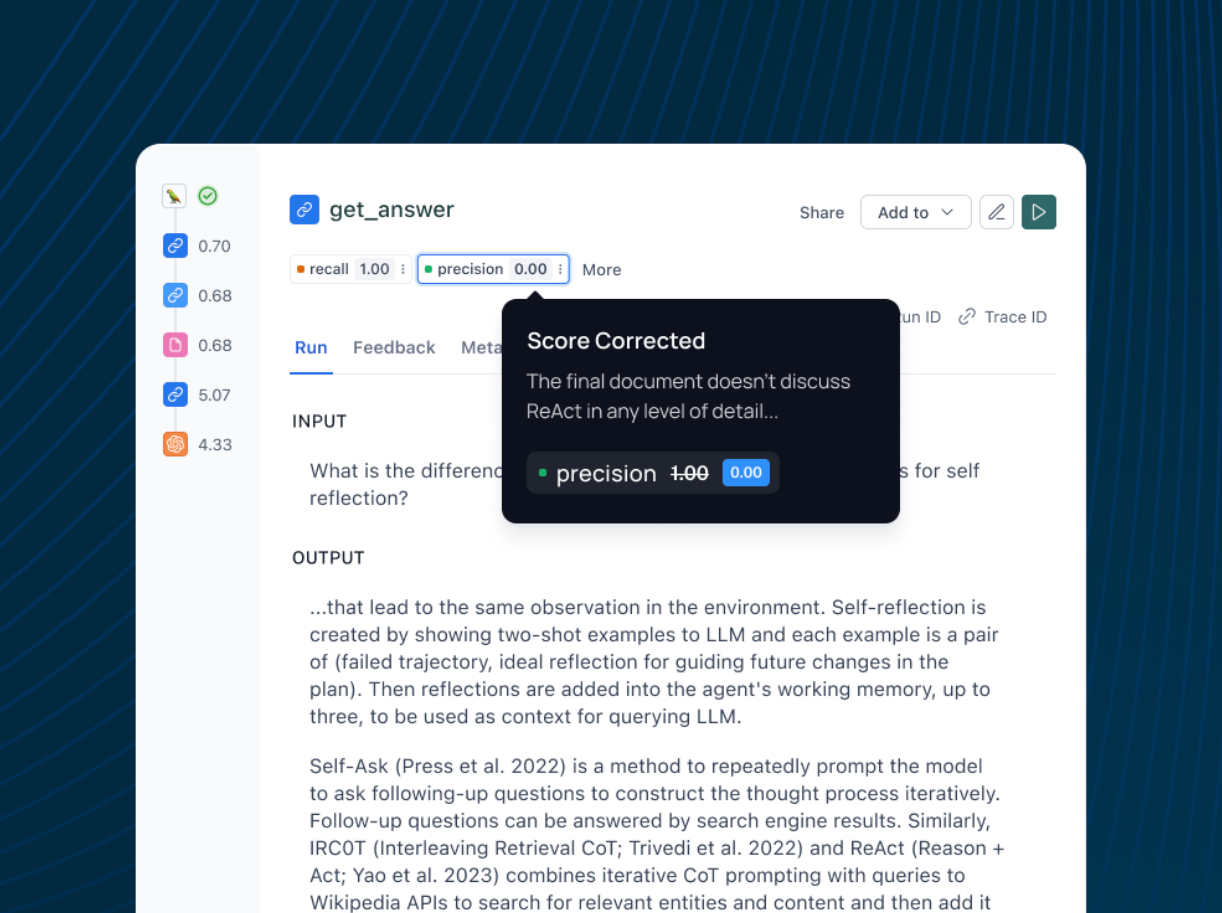
Using an “LLM-as-a-Judge” is a popular way to grade outputs from LLM applications. This involves passing the generated output to a separate LLM and asking it to judge the output. But, making sure the LLM-as-a-Judge is performing well requires another round of prompt engineering. Who is evaluating the evaluators? 
LangSmith addresses this by allowing users to make corrections to LLM evaluator feedback, which are then stored as few-shot examples used to align / improve the LLM-as-a-Judge. Improve future evaluation without manual prompt tweaking, ensuring more accurate testing.
Learn more in our blog.